

Clinical Document Architecture
2.0.1-sd-202510-matchbox-patch - release
Clinical Document Architecture
2.0.1-sd-202510-matchbox-patch - release
Clinical Document Architecture - Local Development build (v2.0.1-sd-202510-matchbox-patch) built by the FHIR (HL7® FHIR® Standard) Build Tools. See the Directory of published versions
The HL7 Clinical Document Architecture (CDA) is a document markup standard that specifies the structure and semantics of "clinical documents" for the purpose of exchange. A clinical document is a documentation of clinical observations and services, with the following characteristics:
A CDA document is a defined and complete information object that can include text, images, sounds, and other multimedia content.
Key aspects of the CDA include:
The scope of the CDA is the standardization of clinical documents for exchange.
The data format of clinical documents outside of the exchange context (e.g., the data format used to store clinical documents) is not addressed in this specification.
CDA documents can be transmitted in HL7 messages designed to transfer clinical documents. While the detailed specification for such messages is outside of the scope of the CDA, this specification does impose requirements upon the packaging of CDA documents in HL7 messages.
The CDA does not specify the creation or management of documents, only their exchange markup. While it may be possible to directly use the CDA Schema in a document authoring environment, such use is not the primary purpose of the CDA specification.
Document management is critically interdependent with the CDA specifications, but the specification of document management messages is outside the scope of the CDA. (For more on this, see Relationship of the CDA to HL7 Messaging Standards).
NOTE: Several committees are developing structured document specifications that overlap in part with the CDA specification. The Structured Documents Technical Committee, in collaboration with Publishing and these other committees, is developing a Structured Documents Infrastructure chapter to clarify these relationships which should be available in upcoming editions.
The goals of the CDA are:
A number of design principles follow from consideration of the above goals:
This section serves as a high-level introduction to the major components of a CDA document, all of which are described again and in greater detail later on. The intent here is to familiarize the reader with the high-level concepts to facilitate an understanding of the sections that follow.
Major components of a prototypic CDA document are shown in the following skeletal example. (Note that many required components are missing to simplify the example. See Examples for a detailed conformant example).
A CDA document is wrapped by the <ClinicalDocument> element, and contains a header and a body. The header lies between the <ClinicalDocument> and the <structuredBody> elements, and identifies and classifies the document and provides information on authentication, the encounter, the patient, and the involved providers.
The body contains the clinical report, and can be either an unstructured blob, or can be comprised of structured markup. The example shows a structured body, which is wrapped by the <structuredBody> element, and which is divided up into recursively nestable document sections.
A CDA document section is wrapped by the <section> element. Each section can contain a single narrative block (see Section Narrative Block), and any number of CDA entries and external references.
The CDA narrative block is wrapped by the <text> element within the <section> element, and must contain the human readable content to be rendered. See also Human Readability and Rendering CDA Documents and CDA Conformance for principles governing the representation of the narrative block, and conformance requirements on the part of originators when populating the block, and recipients when rendering it.
Within a document section, the narrative block represents content to be rendered, whereas CDA entries represent structured content provided for further computer processing (e.g. decision support applications). CDA entries typically encode content present in the narrative block of the same section. The example shows two <observation> CDA entries, and a <substanceAdministration> entry containing a nested <supply> entry, although several other CDA entries are defined.
CDA entries can nest and they can reference external objects. CDA external references always occur within the context of a CDA entry. External references refer to content that exists outside this CDA document - such as some other image, some other procedure, or some other observation (which is wrapped by the <externalObservation> element). Externally referenced material is not covered by the authentication of the document referencing it.
Example 1
<ClinicalDocument>
... CDA Header ...
<structuredBody>
<section>
<text>...</text>
<observation>...</observation>
<substanceAdministration>
<supply>...</supply>
</substanceAdministration>
<observation>
<externalObservation>...
</externalObservation>
</observation>
</section>
<section>
<section>...</section>
</section>
</structuredBody>
</ClinicalDocument>
The notion of CDA "levels" in CDA, Release One anticipated a hierarchical set of XML DTDs or XML Schemas to achieve the goals enumerated above (see Goals and Design Principles). This hierarchy formed an "architecture", hence the "A" in "CDA".
While the notion of levels in CDA, Release Two remains constant, the approach to representing the hierarchies has changed. The current specification consists of a single CDA XML Schema, and the architecture arises from the ability to apply one or more of a hierarchical set of HL7 Templates, which serve to constrain the richness and flexibility of CDA.
NOTE: The CDA can be constrained by mechanisms defined in HL7 V3 Refinement and Localization. HL7 technical formalisms (e.g. HL7 Template specifications, HL7 Model Interchange Format) to constrain CDA are still in development at the time of writing this standard.
The RIM's InfrastructureRoot class contains an attribute, templateId, which is available for use in CDA. Thus, while HL7 Templates are in flux at this time, CDA provides a mechanism to reference a template or implementation guide that has been assigned a unique identifier. Until there is a formal HL7 Template specification, there is no standardized process to test conformance against referenced templates.
There is no requirement that CDA must be constrained. Implementations that use structured data elements to drive automated processes will typically require that they be either: (1) constrained by an appropriately refined model or other HL7 approved constraint language; or (2) comply with a detailed implementation guide that details the manner in which structured elements are to be represented and their intended interpretation to a level sufficient to ensure a degree of clinical safety that is appropriate to the use case that it is designed to address.
There are many kinds of HL7 Templates that might be created. Among them, two are particularly relevant for clinical documents: (1) those that constrain the document sections based on the type of document (section-level templates); (2) those that constrain the entries within document sections (entry-level templates). In fact, a comparison can be made between the prior notion of CDA levels and the current notion of CDA with these two kinds of HL7 Templates:
Table 1: Evolution of CDA "levels" from CDA, Release One to CDA, Release Two
| CDA, Release One | CDA, Release Two |
|---|---|
| CDA Level One | The unconstrained CDA specification. |
| CDA Level Two | The CDA specification with section-level templates applied. |
| CDA Level Three | The CDA specification with entry-level (and optionally section-level) templates applied. |
An illustration of one possible hierarchy of CDA plus HL7 Templates is shown here:
Example 2
The CDA requirement for human readability guarantees that a receiver of a CDA document can algorithmically display the clinical content of the note on a standard Web browser. CDA, Release Two, with its blend of narrative and CDA entries, presents new challenges to this requirement.
Among the requirements affecting the design of CDA Release 2 are the following:
These principles and requirements have led to the current approach, where the material to be rendered is placed into the Section.text field (see Section Narrative Block). The content model of this field is specially hand crafted to meet the above requirements, and corresponds closely to the content model of sections in CDA, Release One. Structured observations can reference narrative content in the Section.text field. Multimedia observations are encoded outside the Section.text field, and the <renderMultiMedia> tag within the Section.text field provides an outgoing pointer that indicates where the referenced multimedia should be rendered.
XML markup of CDA documents is prescribed in this specification. CDA instances are valid against the CDA Schema and may be subject to additional validation (see CDA Conformance). There is no prohibition against multiple schema languages (e.g., W3C, DTD, RELAXNG), as long as conforming instances are compatible.
Design Principles of the CDA Schema include:
Document Analysis: The CDA Schema and conformant instances should adhere to the requirements of document analysis in derivation of the content model.
NOTE: Document analysis is a process that might be thought of as the document equivalent of a use case. Document analysis looks at a single instance or class of documents and analyzes their structure and content, often representing this as a tree structure "elm" notation. Document analysis also looks at the business rules for the lifecycle of that document or document class. Traditionally, document analysis determines the content model and overall structure and style of XML.
Document analysis is an iterative step in content model derivation – the "bottom up" approach to complement the "top down" derivation from the RIM. This will ensure that schemas and instances are not only RIM-derived, but represent recognizable artifacts in a simple manner.
Application systems sending and receiving CDA documents are responsible for meeting all legal requirements for document authentication, confidentiality, and retention. For communications over public media, cryptographic techniques for source/recipient authentication and secure transport of encapsulated documents may be required, and should be addressed with commercially available tools outside the scope of this standard.
The CDA does provide confidentiality status information to aid application systems in managing access to sensitive data. Confidentiality status may apply to the entire document or to specified segments of the document.
A CDA document is a defined and complete information object that can exist outside of a messaging context and/or can be a payload within an HL7 message. Thus, the CDA complements HL7 messaging specifications.
Clinical documents can be revised, and they can be appended to existing documents. Ideally, an updated document would declare itself as obsolete, and would contain an explicit pointer to a more recent version. This would lessen the chances of a healthcare provider basing treatment decisions on erroneous or incomplete data.
In practice, however, it is impossible to guarantee an explicit forward pointer from an outdated version to the newer version. Without a process that tracks the chain of custody of clinical documents and all of their copies, there can be no way to guarantee that a clinical document being viewed has not been subsequently revised.
To minimize the risk of viewing superseded information, there is a critical interdependence between clinical documents and document management systems. If CDA documents are viewed outside the context of a document management system, it cannot be known with certainty whether or not the viewed document has been revised. HL7 messages that carry CDA documents (such as the MDM messages in HL7 V2.x and the HL7 V3 Medical Records messages) convey critical contextual information that ensures accurate viewing of clinical data.
NOTE: See HL7 V3 Refinement and Localization for a complete discussion of V3 conformance.
A conformant CDA document is one that at a minimum validates against the CDA Schema, and that restricts its use of coded vocabulary to values allowable within the specified vocabulary domains. However a computer cannot validate every aspect of conformance. The focus of this section is to highlight these aspects of CDA that cannot be machine validated - particularly those aspects related to the CDA human readability requirements.
A document originator is an application role that creates a CDA document. CDA documents can be created via transformation from some other format, as a direct output of an authoring application, etc. The document originator often is responsible for communicating with a persistent storage location, often using HL7 V2 MDM or HL7 V3 Medical Records messages. The document originator is responsible for ensuring that generated CDA documents are fully conformant to this specification.
A document recipient is an application role that receives status updates and documents from a document originator or document management system. The document recipient is responsible for ensuring that received CDA documents are rendered in accordance to this specification.
Because CDA is an exchange standard and may not represent the original form of a document, there are no persistent storage requirements for CDA documents defined in this standard. However, as noted above (see Relationship of the CDA to HL7 Messaging Standards), document management is critically interdependent with the CDA specification. The custodian identified in the CDA header is the participant charged with maintaining the original document, which may be in some form other than CDA.
Locally-defined markup may be used when local semantics have no corresponding representation in the CDA specification. CDA seeks to standardize the highest level of shared meaning while providing a clean and standard mechanism for tagging meaning that is not shared. In order to support local extensibility requirements, it is permitted to include additional XML elements and attributes that are not included in the CDA schema. These extensions should not change the meaning of any of the standard data items, and receivers must be able to safely ignore these elements. Document recipients must be able to faithfully render the CDA document while ignoring extensions.
Extensions may be included in the instance in a namespace other than the HL7v3 namespace, but must not be included within an element of type ED (e.g., <text> within <procedure>) since the contents of an ED datatype within the conformant document may be in a different namespace. Since all conformant content (outside of elements of type ED) is in the HL7 namespace, the sender can put any extension content into a foreign namespace (any namespace other than the HL7 namespace). Receiving systems must not report an error if such extensions are present.
When these extension mechanisms mark up content of general relevance, HL7 encourages users to get their requirements formalized in a subsequent version of the standard so as to maximize the use of shared semantics.
The basic model of CDA, Release Two is essentially unchanged. A CDA document has a header and a body. The body contains nested sections. These sections can be coded using standard vocabularies, and can contain CDA entries. The main evolutionary steps in CDA, Release Two are that both header and body are fully RIM-derived, and there is a much richer assortment of entries to use within CDA sections. CDA, Release Two enables clinical content to be formally expressed to the extent that it is modeled in the RIM.
This section describes the types of changes that can be introduced to a new release of CDA and CDA principles of forward and backward compatibility. In general, changes can include the addition of new components; a renaming of components (including XML element and attribute names in the CDA Schema); a deprecation of components defined in a prior release; a change in cardinality of a component (either to tighten or to loosen); or a change in a vocabulary domain of a component (to add or change values, to change between CWE and CNE). The following set of guiding principles defines how CDA can continue to evolve, while protecting the investment implementers have made through their adoption of earlier releases.
These guiding principles have lead to the current approach, defined in this Release Two of the CDA standard. The goal is to ensure that the documents created using Release One can be transformed into minimally compliant Release Two instances and that Release Two documents received can be down-translated to Release One instances using automated means (transformations) with no loss of attested, human-readable content and known limitation on loss of universal processing semantics.
CDA context is set in the CDA header and applies to the entire document. Context can be overridden at the level of the body, section, and/or CDA entry.
A document, in a sense, is a contextual wrapper for its contents. Assertions in the document header are typically applicable to statements made in the body of the document, unless overridden. For instance, the patient identified in the header is assumed to be the subject of observations described in the body of the document, unless a different subject is explicitly stated, or the author identified in the header is assumed to be the author of the entire document, unless a different author is explicitly identified on a section. The objective of the CDA context rules are to make these practices explicit with relationship to the RIM, such that a computer will understand the context of a portion of a document the same way that a human interprets it.
At the same time, there is no guarantee that machine processing will identify a mistaken application of contextual rules. If a physician records an "outside diagnosis" in narrative but does not nullify the "informant" context, machine processing will not identify the switch in attribution. This is a special case illustrating the limits of automated validation of electronic records and would apply regardless of the context inheritance mechanism. In other words, from some errors of encoding, there is no recovery other than human review.
CDA's approach to context, and the propagation of that context to nested document components, follows these design principles:
The RIM defines the "context" of an act as those participants of the act that can be propagated to nested acts. In the RIM, whether or not contextual participants do propagate to nested acts depends on whether or not the intervening act relationship between parent and child act allows for conduction of context. The explicit representation of context, and whether or not the context on an act can propagate to nested acts, is expressed via the RIM attributes Participation.contextControlCode and ActRelationship.contextConductionInd. CDA constrains the general RIM context mechanism such that context always overrides and propagates, as shown in the following table.
| RIM attribute | Cardinality | Conformance | Fixed Value |
|---|---|---|---|
| Participation.contextControlCode | 1..1 | Mandatory (NULL values not permitted) | "OP" (overriding, propagating) |
| ActRelationship.contextConductionInd | 1..1 | Mandatory (NULL values not permitted) | "true"* |
* The one exception to this is entryRelationship.contextConductionInd, which is defaulted to "true", but can be changed to "false"
Where the context of a nested component is unknown, the propagated context must be overridden with a null-valued component, as shown in the following table.
| Context | Null value representation | |
|---|---|---|
| Author | AssignedAuthor.id = NULL | No playing entity; No scoping entity. |
| Confidentiality | confidentialityCode = NULL | |
| Human language | languageCode = NULL | |
| Informant | AssignedEntity.id = NULL | No playing entity; No scoping entity. |
| Participant | ParticipantRole.id = NULL | No playing entity;No scoping entity. |
The following exhibit illustrates the CDA context model. ClinicalDocument has an author participant, a confidentialityCode, and a languageCode, all of which will propagate to nested acts. The component act relationship going from ClinicalDocument to bodyChoice has contextConductionInd fixed as "true", thus allowing for the propagation of context. The bodyChoice classes, NonXMLBody and StructuredBody, contain a confidentialityCode and languageCode which can be used to override the value specified in the header. The component act relationship going from StructuredBody to Section has contextConductionInd fixed at "true", thus the context on StructuredBody will propagate through to Section. Section can override confidentialityCode, languageCode, and author. A null value for the Section's author participant indicates that the author for that particular section is unknown.
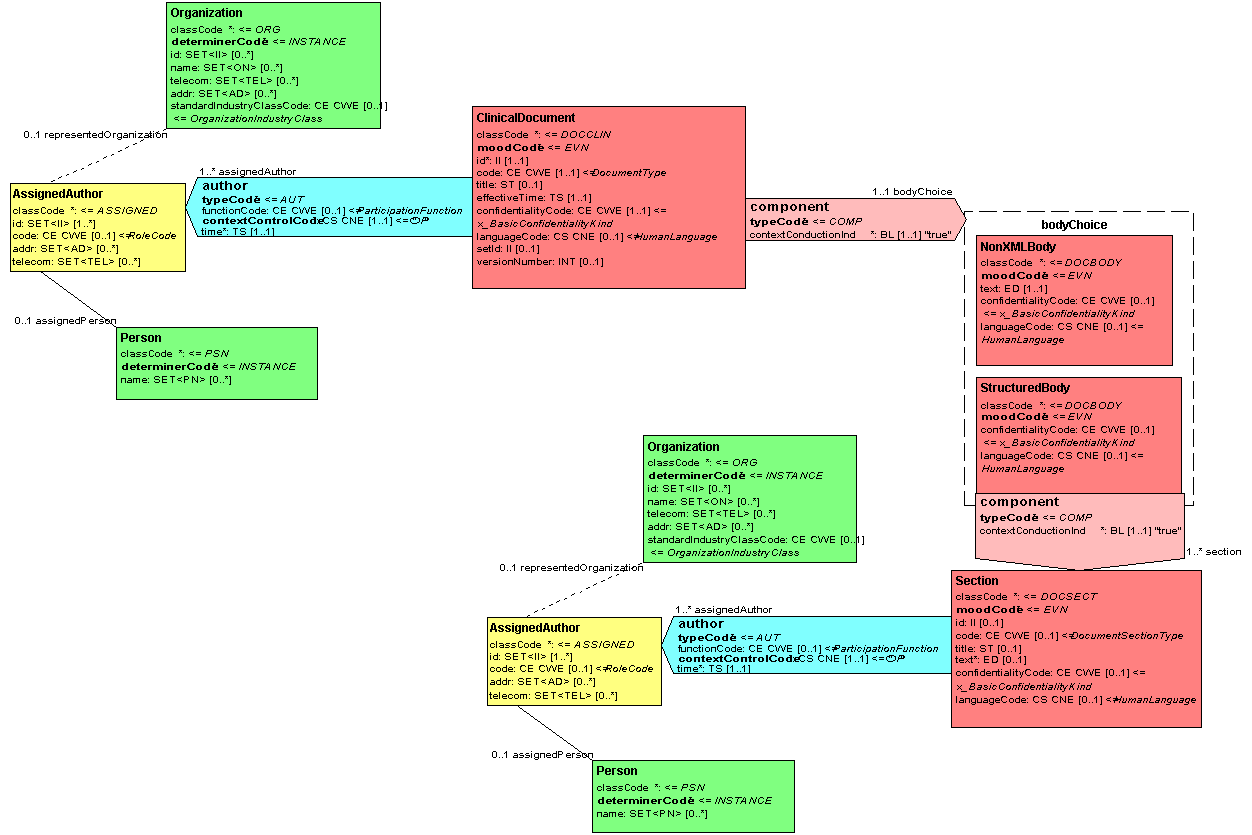
Because context is always overriding and propagating, one can compute the context of a given node by looking for the most proximate assertion. The following example is a sample XPath expression that can be used to identify the <author> context of a section or entry:
(ancestor-or-self::*/author)[position()=last()]
IG © 2019+ Health Level 7. Package hl7.cda.uv.core#2.0.1-sd-202510-matchbox-patch based on FHIR 5.0.0. Generated 2025-10-29
Links: Table of Contents |
QA Report
| Version History  |
|
 |
Propose a change
|
Propose a change